On-device assistant
Stela
An assistant that learns you, gets smarter over time, works instantly and doesn't require the cloud.
Your Personal AI
Weather / Locations / Directions / Scheduling / Translation / Maths / Knowledge Management / Ad-Hoc Fine-Tuning
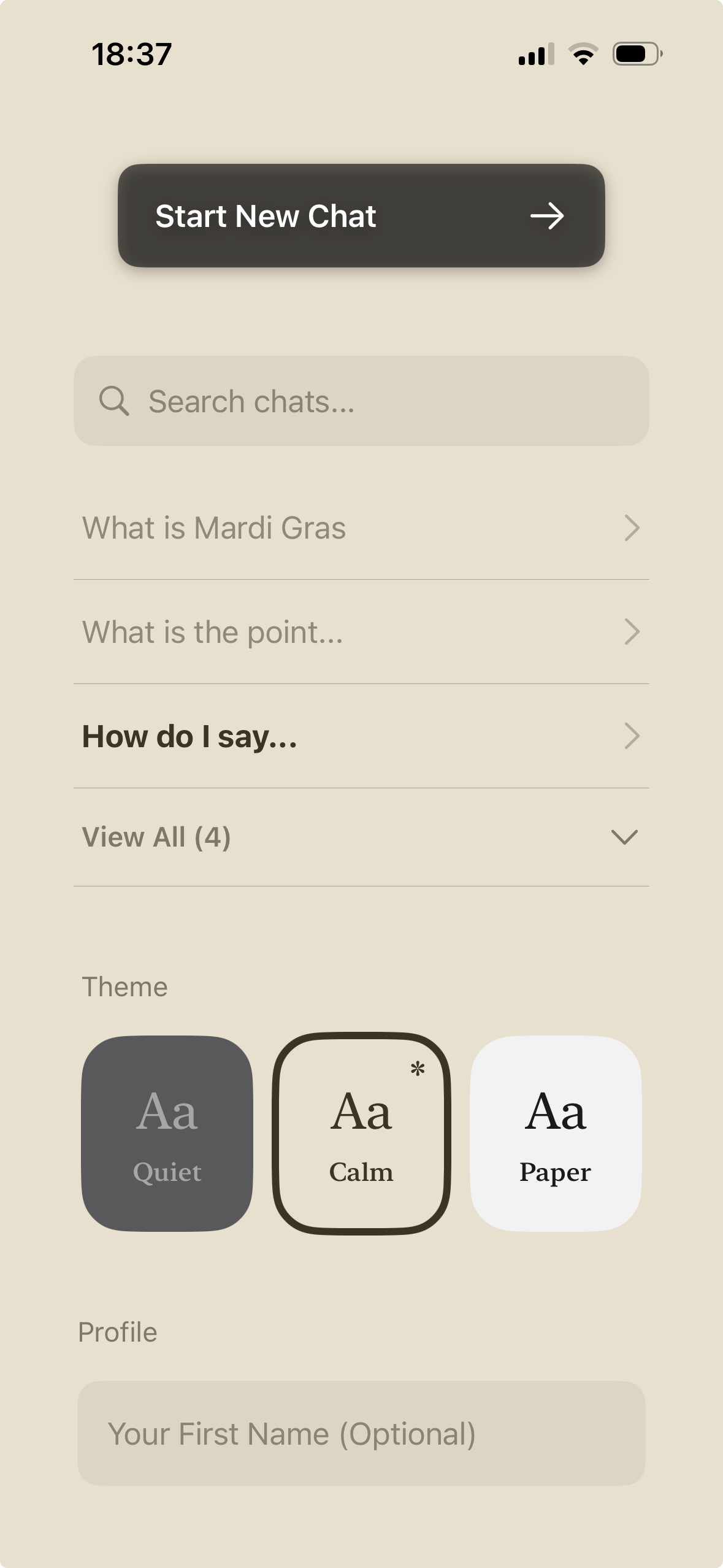
Readable
Careful Design
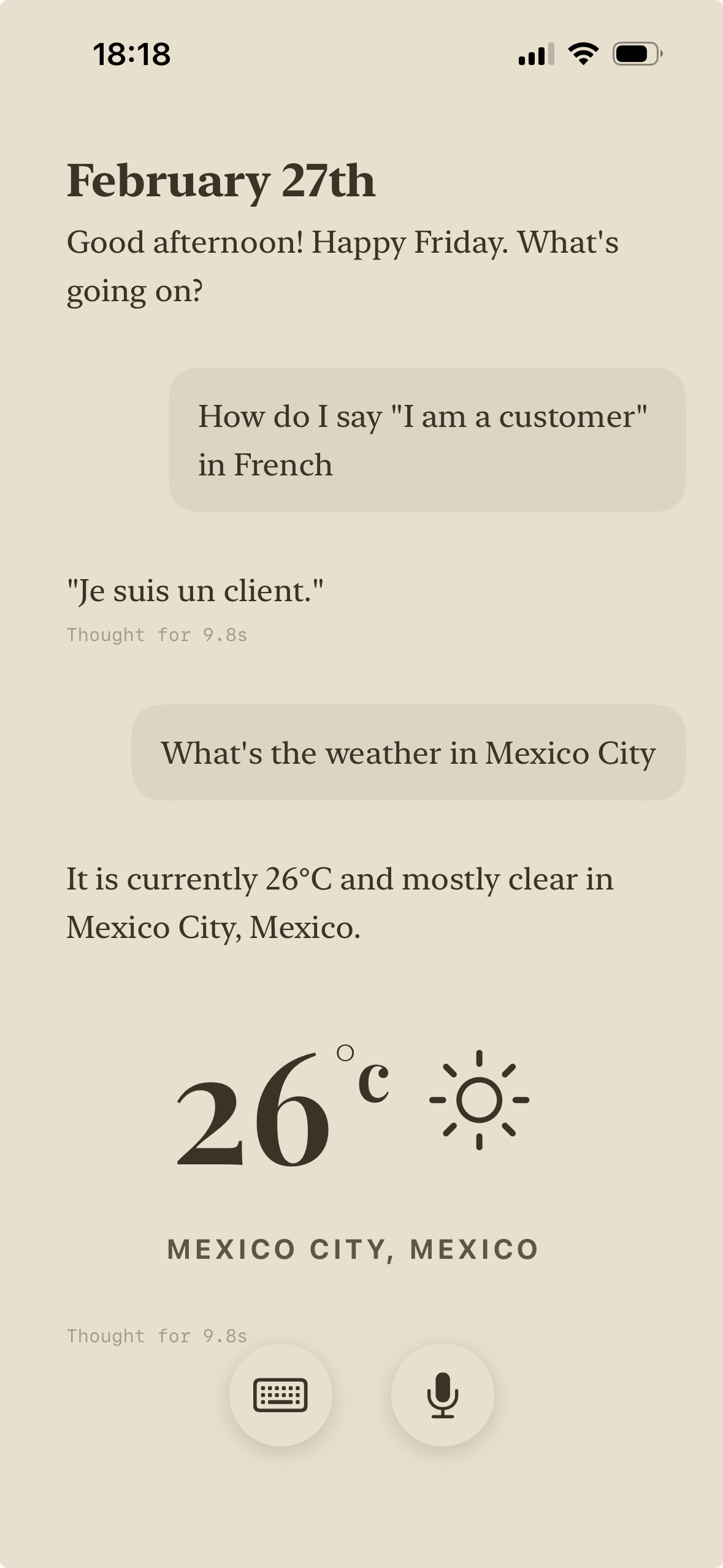
Fluent
Interact Naturally
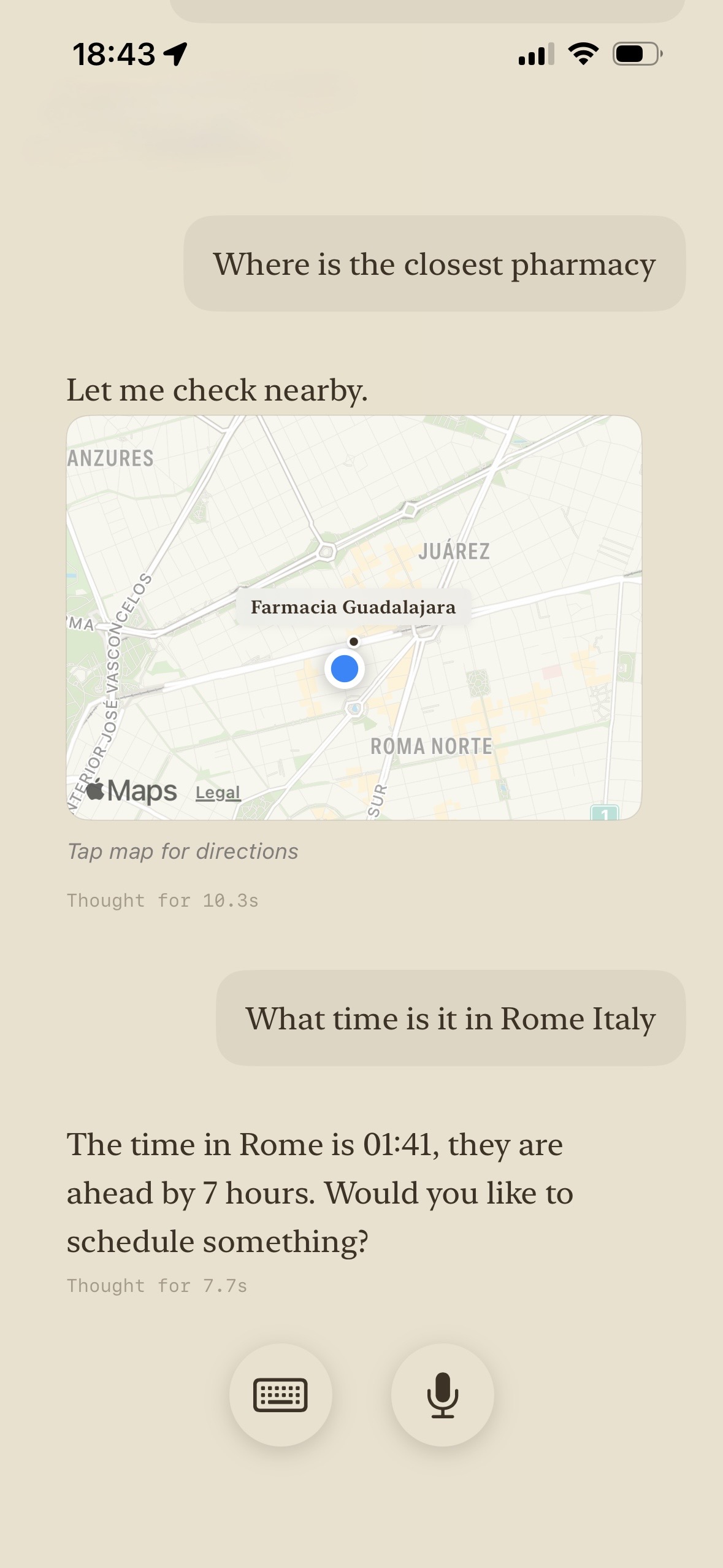
Current
Optionally Connected
Structural Memory
Unlike products like ChatGPT that can remember things like “User prefers concise answers.” Stela builds a connected graph that models Goals, Constraints, Values, Rules and their Relationships.
-
Constraint-aware decisions
It can detect tradeoffs (e.g., spending vs savings goal) because relationships are explicit. -
Cross-domain reasoning
Fitness, money, work, stress — connected instead of siloed conversations. -
Executable rules
“If I’m stressed, slow me down.”
“If purchase > $200, add a 24-hour delay.”
Not remembered — applied. -
Stability over time
No context drift. Nodes and edges persist. Reasoning stays anchored. -
Inspectability
You can see and modify what it “believes,” which builds trust.
Private by default
-
Private by default
Sensitive texts, photos, location, health, or financial data can stay completely local. -
Not manipulative
The same people who work to make gambling and social media addictive are now working on AI. Stela keeps it boring, avoiding manipulative behaviors, sudden changes or policy shifts. -
Lower breach risk
No central server storing your data = smaller attack surface. -
Reduced tracking & profiling
Minimizes behavioral telemetry collected by platforms or advertisers. -
Customizable safety policies
Users or organizations can tune guardrails locally to their values or compliance needs.
Programmability
Stela is programmable. You are completely in control.
Effecency
-
No Internet Required
Reliable in planes, subways, rural areas, disasters, or censorship environments. On-device inference means no network latency. -
Fixed Cost
No API fees, subscriptions, or usage caps tied to cloud compute. -
Energy & Bandwidth
No constant data transfer; better for low-bandwidth or metered environments. -
Autonomy
Useful in field work (journalists, researchers, military, humanitarian aid) where connectivity is unreliable or monitored.
Interpretation
A safety-first assistant designed for local inference and fully inspectable, programmable, priority-memory without hidden agendas or advertising.
Motivation
Stela is an acronym for Safety Tuned Epistemic Learning Agent.
-
Data Sovereignty
Your data stays under your legal jurisdiction and personal control. -
Emergencies
Critical guidance (first aid, evacuation info, crisis coping tools) available offline. -
Parental / Youth Safety
On-device guardrails without sending children’s data to external servers. -
Corporate / Regulated Use
Safer for legal, medical, defense, or trade-secret contexts where cloud use is restricted. -
Censorship Resistance
Access to scientific understanding and basic education continues functioning even if specific online-only services are blocked.